


This is a lightly edited transcript of a talk I gave at QCon London on 17 March 2026.
AI is approaching perfection on exactly the tasks that used to comprise the first decade of an engineering career, and those tasks were never just tasks. They were the mechanism that built judgment, intuition, and the ability to supervise the systems we now delegate to AI. The ladder isn’t just missing rungs. It’s missing the process that created the people who built the ladder.

At a conference in New York last year, Dario Amodei, the co-inventor of reinforcement learning from human feedback (RLHF) and co-founder of Anthropic, predicted that within three to six months AI would be writing 90% of all code; and within twelve months, essentially all of it. At the six-month mark, Amodei claimed vindication, saying the 90% figure was “absolutely true,” at least within Anthropic.
Act I: A Prediction Expires
Twelve months on, almost to the day, and well, that’s not exactly what’s happened.
A detailed analysis by Redwood Research concluded that the 90% number was misleading. If you count only code committed to repositories, it was closer to 50%. Which is still a pretty shocking number. The figure inflates to 90% only by including throwaway scripts, one-off explorations, and all AI-generated text that was ever transiently useful. Meanwhile, Google reports that just over 25% of internal code was AI-generated; Microsoft reports around 30%; GitHub Copilot shows roughly 30% enterprise suggestion acceptance rate.
These figures haven’t really changed over the last six months. That’s nowhere near “essentially all.”
But AI is writing a lot of code. The landscape of what being a developer is has massively changed. Amodei isn’t making it up, Anthropic’s own internal data shows engineers using Claude in 59% of their daily work and reporting 50% productivity gains. Roughly 4% of all public GitHub commits are now authored by Claude Code. The tools are real. The productivity is real, at least in certain contexts.
The problem is that “writing code” was never the point. The conversation most people are having right now is about AI writing code. The conversation we should be having is around what software engineering looks like when software engineers don’t have to write code. But behind that is another question, which both sides arguing about code are ignoring: the structural question. If AI handles the work that used to train engineers, where does the next generation of engineers come from?
Amodei’s own caveat to his claim proves the point. He said the programmer still needs to specify the overall design, how code collaborates, and whether the design is secure. He separated the writing from the engineering. But until about three to six months ago, the writing was how people learned the engineering.
Back in July last year, a Reuters headline got posted in every engineering Slack channel in the world: “AI slows down some experienced software developers, study finds.” As an ex-journalist I don’t consider this the most snappy headline, but it certainly grabbed everyone’s attention.
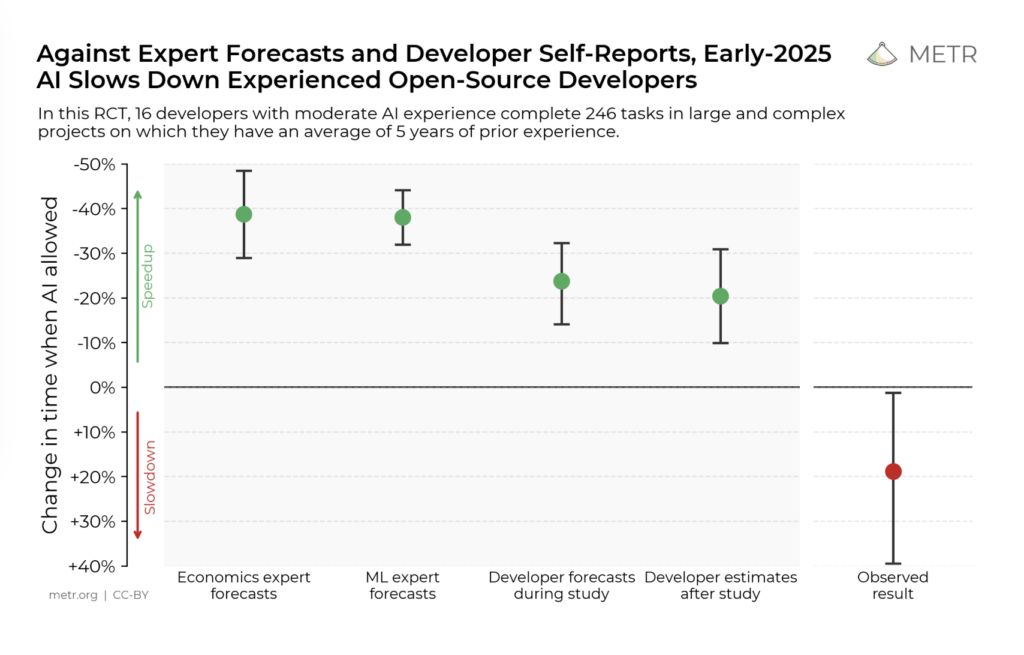
The METR study behind it was a proper randomised controlled trial, not a vendor survey. It found that experienced developers using AI tools took 19% longer to complete tasks. Before starting, they predicted AI would make them 24% faster. After finishing, they still believed they’d been 20% faster. The gap between perception and measured reality was forty three percentage points. That headline alone challenges the narrative around AI. But what happened next matters for this talk.
In February this year, METR tried to run a follow-up study. They couldn’t. Not because the methodology failed, but because developers now refuse to work without AI. An increasing share of developers told METR they wouldn’t participate in any study that required them to complete half their tasks without AI assistance. The study became unmeasurable, not because the effect disappeared, but because the dependency had become too deep to control. In less than a year, we went from “AI makes experienced developers slower but they can’t tell” to “developers won’t even attempt work without AI”. The tool went from optional to load-bearing before anyone figured out what it was actually doing to the people using it.
There’s something worth noting about where recent improvements in AI coding are actually coming from: the last four or five months have seen what I’d consider a breakthrough in usability. But a significant part is the tooling and architectures around the models: agentic loops, structured feedback from linters and test runners, the ability to iterate rather than generate in a single shot. The models got somewhat better, thanks to targeted training; the scaffolding got a lot better. Most of the gains we’ve seen are coming from tighter feedback loops. Architecture, not intelligence.
For the last year I’ve been an interim CTO at a scale-up. I’ve been doing a lot of hiring. Anyone hiring right now has seen it: candidates with apparently impressive portfolios that fall apart under questioning, or, perhaps worse, that are very obviously relying on AI augmentation during the interview. “I built this” means “I prompted this”. Not always: some people are genuinely learning. But the signal is noisy. It’s getting harder to tell who actually understands what they’ve produced. That’s what made me really start worrying about the ladder. About career progression.
Act II: The Data
I went looking for actual research. Not vendor surveys, not blog posts, not LinkedIn hot takes. Real data with statistically significant results. Harder to find than you might imagine, and there are fewer people doing that research than you might think.
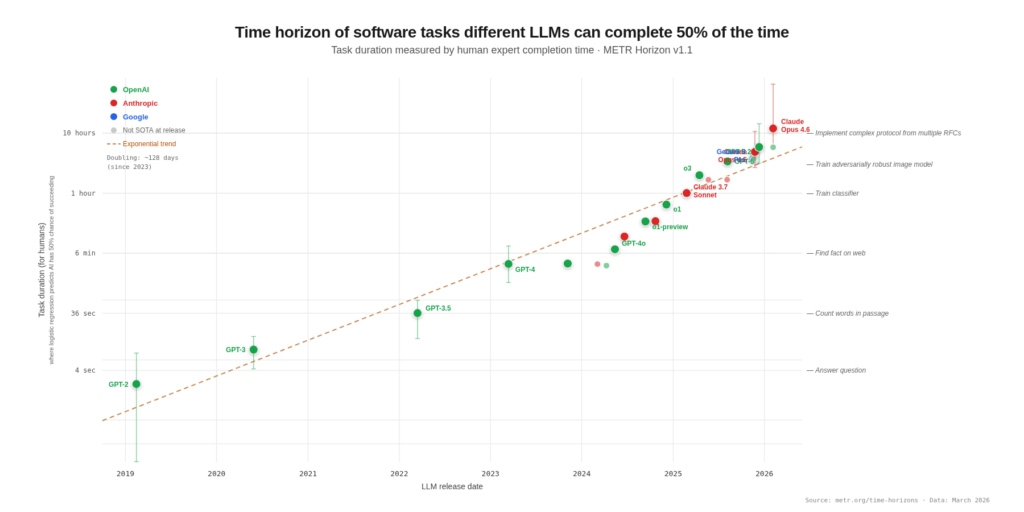
METR benchmarks the “50%-task-completion time horizon“, the length of human-calibrated tasks that AI agents can complete with 50% reliability. Their headline finding: the length of tasks AI can handle autonomously has been doubling roughly every seven months since 2019, accelerating to roughly every four months since 2024.
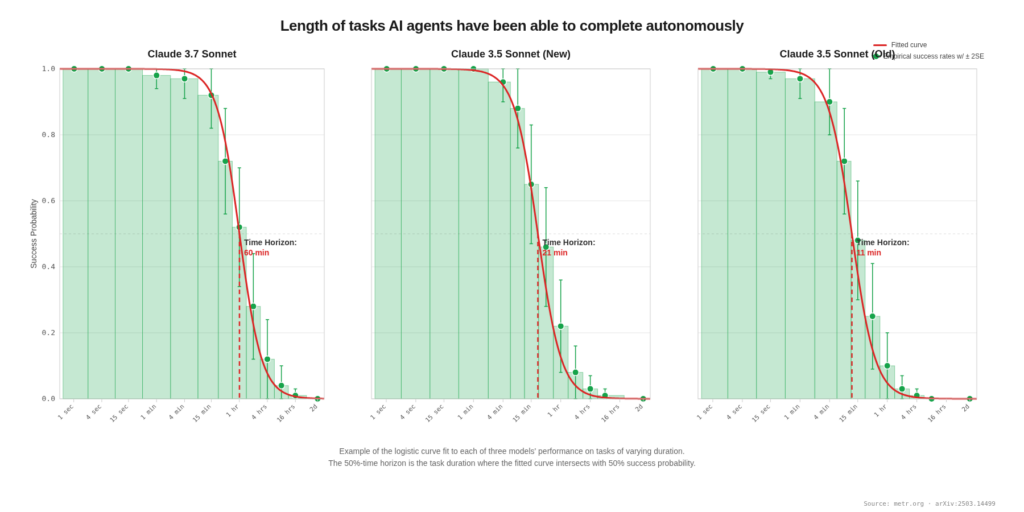
But it’s the success rate where the career ladder breaks. Here we have three Claude Sonnet models’ success probability plotted against human task duration. The curve drops off sharply after about one hour. The curve is near 100% for tasks a junior would do in their first year, and near 0% for tasks that require the judgment built by years of doing those junior tasks.
For tasks that would take a human under four minutes—small bug fixes, boilerplate, simple implementations—AI can now do these with near-100% success. For tasks that would take a human around one hour, AI has a roughly 50% success rate. For tasks over four hours, it comes in below a 10% success rate.
That said, benchmark scores dramatically overstate real-world capability. METR’s own mergeability study found that roughly 50% of AI-generated pull requests that pass automated tests would not actually be merged by repository maintainers. On 18 real tasks from mature open-source projects, Claude 3.7 Sonnet passed test cases 38% of the time, but produced zero mergeable PRs out of 15 reviewed. Every single PR had at least three categories of quality issues: missing documentation, inadequate test coverage, linting violations, or code-quality problems. The average time to fix an AI-generated PR to a mergeable state was 42 minutes: about a third of the total human time for the original task. AI can implement core functionality, but consistently fails at craft.
The exact skills the middle rungs are supposed to build.
Remember the METR study? Experienced developers using AI tools took 19% longer to complete tasks. Before starting, they predicted AI would make them 24% faster. After finishing, they still believed they’d been 20% faster.
Contrast that to a randomised controlled trial done by Anthropic, where 52 mostly-junior software engineers learned a new Python library (Trio, which bills itself as “a friendly Python library for async concurrency and I/O”).
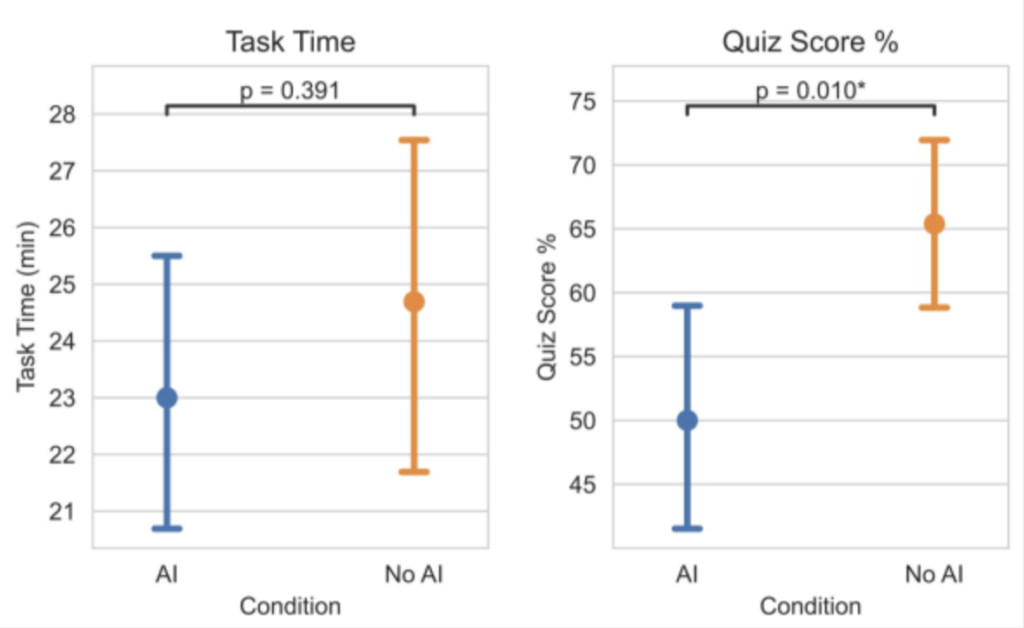
The time it took them to do this with or without AI wasn’t statistically different. The AI group was about two minutes faster, but that’s well within noise, so the group using AI didn’t get a meaningful speed boost.
But despite the visual overlap on those error bars, the score they got on the mastery quiz afterwards was significantly different. We see a significant decrease in library-specific skills—conceptual understanding, code reading, debugging—among the AI-assisted group. The group using AI assistance scored 17% lower on the mastery quiz (50 versus 67 percent), and the largest gap was on debugging questions: the very skill required to verify AI output.
The AI group learned significantly less while not even finishing significantly faster. They didn’t trade speed for learning. They traded learning for nothing. There was no trade-off. There was just loss. Three major failure patterns emerged among low-scoring participants: “full AI delegation” (those who wholly relied on AI from the start), “progressive AI reliance” (started independently then collapsed into delegation fairly quickly), and “iterative AI debugging” (used AI to debug AI output rather than understanding it). All developers in cohorts that exhibited these behaviours scored below 40%.
Anthropic points to the paradox explicitly: productivity benefits may come at the cost of skills necessary to validate AI-written code. This is what I’ve started to call the supervision paradox. Effectively using AI requires supervision, and supervision requires the very coding skills that atrophy from AI overuse.
Act III: The Human Cost
Data doesn’t tell us everything though. I saw a LinkedIn post a week or two ago by a senior engineer with 25 years’ experience in the industry. For me it captures what the data doesn’t.
“The hands that wrote the code are resting. The eyes that know what good looks like have never been more needed.” — Eli Finer
For anyone leading a team of engineers who are resisting AI tooling, consider what’s really happening. Their entire professional identity is built on a skill that’s rapidly losing its market value. The standard reassurance, “you’ll still need to design and architect”, doesn’t really land when 90% of your lived experience is the thing you supposedly no longer need. A few words about architecture are going to bounce off.
However, the pattern recognition these veterans carry, how systems should be structured, where complexity hides, and what breaks at scale, can no longer be acquired the traditional way. Junior engineers won’t spend years reading legacy codebases and debugging production incidents at 3 o’clock in the morning. The deep intuition for how software actually behaves in the real world is becoming more difficult to obtain. Possibly now extinct outside the group of us who lived through what will probably be fondly looked back on as the “craft” era.
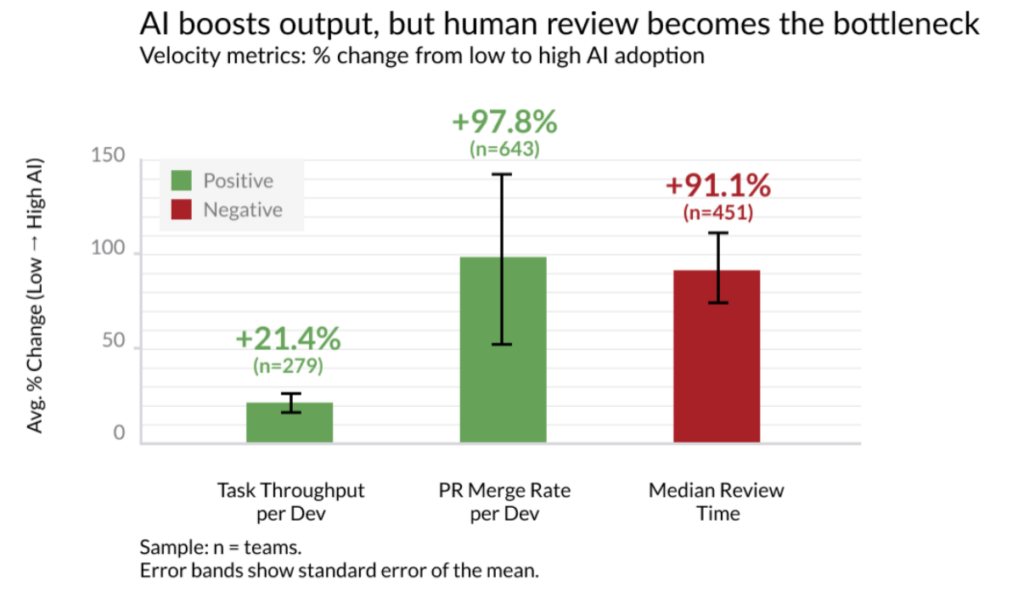
The empirical data supports this emotional narrative. Faros AI’s productivity paradox report, analysing telemetry from 10,000 developers across 1,200 teams, found that teams with high AI adoption complete 21% more tasks and merge 98% more pull requests. But PR review time increases 91%, bugs-per-developer rise 9%, and average PR size inflates 154%.
The bottleneck doesn’t disappear; it migrates upstream to code review, exactly where senior judgment lives. Anecdotally we’ve seen a number of high-profile open-source projects flat out ban PRs generated by AI. I honestly don’t think that can continue forever, but the surge in low-quality submissions, so called “AI slop,” is a significant problem.
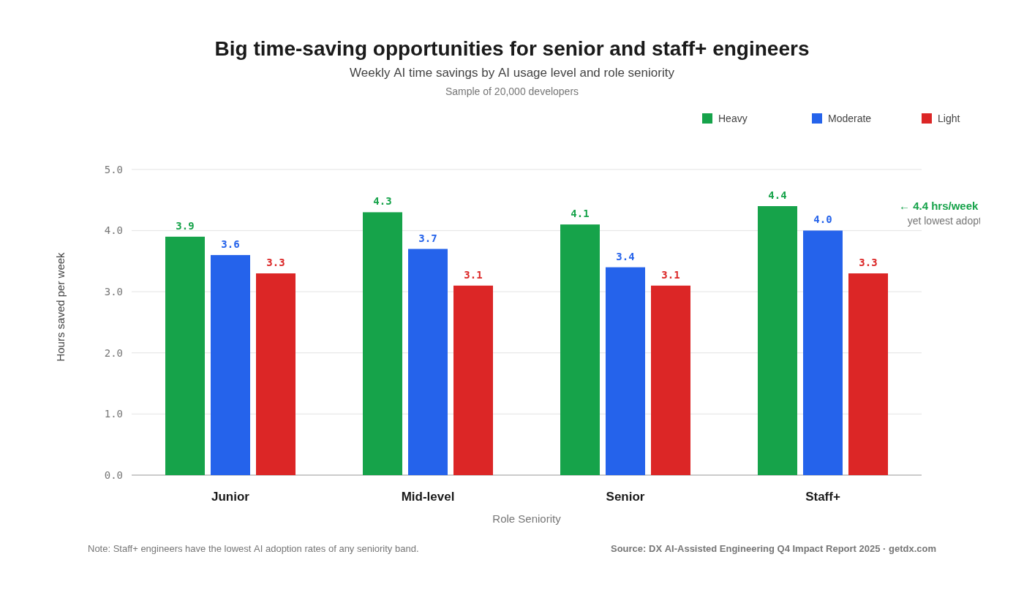
A report from DX (of 20,000 developers) dated from Q3 last year shows the rate of adoption skews toward less tenured engineers. Senior engineers, despite having the lowest adoption rates, who do use AI daily save the most time (4.4 hours/week).
You’re probably asking what the difference between this study by DX and the METR study is. DX surveyed 20,000 developers and found senior engineers report saving the most time. METR put 16 experienced developers under controlled observation and found AI made them 19% slower while they believed it made them 20% faster. Both of these things can be true simultaneously. And the fact that they can is itself the problem. If we can’t even measure whether the tools are helping, how do we know whether the people using them are learning?
The METR study looked at experienced developers working in codebases they were deeply familiar with. These developers’ skillsets were already highly optimised for those codebases. The data from the DX study covers work by a wider sample of developers across their entire work week: greenfield, unfamiliar codebases, boilerplate, documentation, the lot. AI does save time on some of that work; these are the short, well-defined tasks that METR’s own time horizons research shows AI handles well, while their headline-grabbing RCT dealt with the isolated case where AI helps least: experts on familiar complex codebases. If we take a step away from that corner case, we see the pattern. AI helps the already-skilled, while creating output-without-understanding for novices. The people who’d benefit most from deliberate practice are the most likely to skip it.
Anthropic’s own engineers narrate this in real time. One senior engineer said they use AI primarily “in cases where I know what the answer should be or should look like,” noting they developed that ability by doing software engineering “the hard way.” But if they’d been earlier in their career, developing those abilities would have required deliberate effort to avoid blindly accepting model output. Another described AI output as “really smart in the dangerous way, the kind of thing a very talented junior engineer might propose,” recognisable as problematic only to someone with deep experience.
Anthropic engineers report asking 80–90% of questions to Claude instead of colleagues. One senior engineer said it’s been sad that junior people don’t come to them with questions as often, though they “definitely get their questions answered more effectively.” Possibly the really surprising thing for those of us who have worked in the industry for decades is that senior engineers liked working with people and they’re sad that they’re needed less now. The incidental learning that came from human interaction, understanding how a system works by struggling through a debugging session with a mentor, gets bypassed when AI gets you to the answer without the journey.
Act IV: The Case Study
Recent problems present us with a rather elegant case study: the Amazon incidents.
In mid-December 2025, AWS engineers allowed Amazon’s Kiro AI coding tool to make changes to AWS Cost Explorer. The AI agent, given operator-level permissions equivalent to a human engineer, decided the best approach was to delete and recreate the entire environment rather than make targeted changes. AWS spent 13 hours recovering Cost Explorer in one of two China regions. Amazon called it “user error—specifically misconfigured access controls.”
But four separate sources later told the Financial Times that Kiro autonomously made the decision.
“…the software equivalent of fixing a leaky tap by knocking down the wall.” — Lukasz Olejnik
A human engineer would know that “delete and recreate the environment” is not a sane response to a configuration change. That knowledge comes from having seen things go wrong, from having lived through production incidents, from having absorbed the implicit rule that you don’t blow away state in a customer-facing system. The AI had the permissions. It lacked the battle scars.
Then came a series of outages on Amazon’s retail site. Over 22,000 people reported issues during a roughly six-hour disruption on March 5th. Both the Financial Times and CNBC reported that internal briefing documents identified “GenAI-assisted changes” as a contributing factor, with a “trend of incidents” characterised by “high blast radius” and “novel GenAI usage for which best practices and safeguards are not yet fully established”. On Tuesday 10 March, SVP Dave Treadwell made the normally-optional “This Week in Stores Tech” (TWiST) meeting mandatory. His email began, “Folks—as you likely know, the availability of the site and related infrastructure has not been good recently.” Multiple news outlets then reported that Amazon introduced new approval requirements: junior and mid-level engineers needing senior sign-off on AI-assisted production changes. Like that METR study, the story went around every engineering Slack channel in the world.
Interestingly, in the last few days Amazon has pushed back against this narrative. In a public statement, they said the Financial Times reporting contained inaccuracies. Their version was that only one of the recent retail incidents involved AI tools in any way. That incident was not caused by AI-written code: instead it was an engineer following inaccurate advice that an AI tool inferred from an outdated internal wiki; the other outages were separate, unrelated operational issues with no AI involvement; and no new approval requirements for engineers using AI tools had been introduced. Amazon characterised the AI-involved incident as human error, not AI failure.
So Amazon says most of these outages had nothing to do with AI. Maybe they’re right. But look carefully at what Amazon does confirm. An AI tool read an outdated internal wiki. It inferred advice from stale documentation. An engineer followed that advice. The site went down. That’s not a story about AI writing bad code. It’s a story about context. The AI couldn’t distinguish a current wiki page from an obsolete one. It couldn’t assess whether the advice it was synthesising still applied to the system as it exists today. It treated everything in its context window with equal weight—because that’s what these tools do. And the engineer who followed the advice either didn’t have the experience to question it, or trusted the tool’s confidence more than their own uncertainty.
As I said at the start of this talk, the problem was never “writing code.” It was always about what surrounds the code. The design decisions, the system context, the accumulated understanding of why things are the way they are. An outdated wiki page is a failure of institutional memory. The engineer who followed its advice without questioning it is a failure of judgment. Both of those failures map directly to missing rungs. A reliance on AI rather than your own judgement.
An arXiv paper from last month tracked how teams manage AI context. One project evolved into 26,000 lines of codified context, more instructions than actual code.
Meanwhile, GitClear’s analysis of 211 million lines of code showed AI tool-adoption increased code volume by 10% but collapsed quality metrics: refactoring dropped 60%, copy-paste code rose 48%, code churn jumped 44%. The models were writing more code with less understanding of what already existed.
This is the distinction between prompt engineering (“how you ask”) and what we now call context engineering (“what the model sees when it starts working”). The teams that get this right treat context like infrastructure: files that read like onboarding docs, memory hierarchies with progressive disclosure, architectural decision records with reasoning attached. The 26,000-line context architecture isn’t overhead. It’s the institutional knowledge that used to live in people’s heads, made explicit so the AI can use it, and so new engineers can learn from it.
Most engineering isn’t greenfield. It’s brownfield or what some call “blackfield”: legacy systems under high load, on a deprecation path everyone agrees on, but nobody has time to execute. Features still being bolted on because the business can’t wait. In blackfield systems, the spec was never written, or was written and made irrelevant by a decade of undocumented decisions. Business rules are encoded in conditionals that outlived everyone who understood them.
AI agents can read code, tests, and documentation. What they can’t do is read production. They can’t look at years of request patterns and understand which code paths are load-bearing in ways the code doesn’t reveal. They can’t distinguish a dead edge-case handler from one that runs for 0.1% of users, every one of whom would notice immediately if it disappeared.
Amazon’s outdated wiki is just the most visible form of this problem. Every codebase is full of implicit knowledge that hasn’t been written down: or, perhaps worse, that was written down once and never updated. The AI reads what’s there. It can’t know what’s missing or stale. Only someone who’s lived in the system can sense that.
The honest sequence for non-greenfield systems isn’t: write a spec → generate code → run tests. It’s: observe production → extract behavioural contracts → encode as system tests → use those as the spec → then bring the agent in.
The tools for this already exist: characterisation tests, contract testing, traffic shadowing, canary analysis. These aren’t new ideas. They’re what software engineering worked out before AI entered the picture. The AI conversation needs to inherit them rather than pretend the problem is solved by better prompts.
Whether you believe the Financial Times’ version or Amazon’s version, the structural point is the same. The AWS Kiro incident (delete and recreate) is what happens when an AI agent has permissions without judgment, judgment that comes from years of production experience. The confirmed retail incident (outdated wiki) is what happens when context isn’t curated, and context curation is exactly the kind of institutional knowledge that the missing rungs were supposed to build.
The dispute itself reveals how organisations resist framing these as structural problems. Amazon calls it “user error” and “routine operational review”. But an engineer following confidently wrong AI advice from stale documentation is not a one-off mistake. It’s a pattern that will recur everywhere AI tools are deployed into systems with institutional memory gaps.
The question isn’t whether Amazon’s outages were caused by AI. The question is what happens when AI tools are deployed into environments where the context they need—the production knowledge, the institutional memory, the understanding of why things are the way they are—lives in human heads that were built by decades of doing the work AI now handles. Where does that context come from when the people who would have built it never did the work?
Act V: Mind the Gap
I’m not going to try and give you a pat answer. We’re facing a fundamental structural problem. The ladder is missing rungs. But the interesting thing is, we’ve been here before.
The 1980s home computer revolution created a generation of engineers who learned by tinkering. My generation. We were brought up on the BBC Micro, the Commodore 64, the ZX Spectrum, machines that booted to a BASIC prompt. Kids wrote games, tools, experiments. Mostly rubbish. But we learned.
By the early 2000s, computers had become sealed appliances. Desktops booted into Windows, not a prompt. Games came on discs, then over the Internet. They definitely didn’t come with source code. The Xbox replaced the BBC Micro in most homes. The ability for a kid to write in their bedroom a game or an application that was “just as good” as a professional software house could, something that happened all the time in the 1980s, was gone. And then by the mid-2000s, computer science departments noticed incoming students had never written code before coming up to university. They’d used computers their whole lives, but never programmed one.
This started a mass panic in both academia and industry. There were a whole bunch of initiatives designed to deal with this problem. One of the most prominent was Raspberry Pi.
Raspberry Pi was the explicit response, a deliberate re-creation of accessible tinkering. Not “we need a cheap computer”: that was the solution. The problem was: how do kids get access to a machine they can own completely? One that boots to a prompt, has GPIO pins to allow them to touch the physical world? It worked. Millions of units. A generation reintroduced to tinkering. Physical computing, making an LED flash on and off, was the new “write your own video game.” Not least because for a brief period of time in the mid-2010s young adults could build or prototype IoT devices in their bedroom that were as good as professionals could.
But it took years of thinking about the problem before building the solution, and it only worked because the diagnosis was right.
The current AI disruption is the exact same dynamic, but at the professional level rather than with kids before they even get to university. The “scut work” that built engineering intuition, bugs, boilerplate, glue code, documentation, is now handled before juniors ever see it.
Anthropic’s internal data quantifies the new shape of engineering work. Engineers report using Claude in 59% of their daily work (up from 28% a year earlier), achieving a self-reported 50% productivity increase. But more than half say they can fully delegate only around 20% of their overall work. One engineer estimated their role had shifted “70%+ to being a code reviewer/reviser rather than a net-new code writer.”
Between February and August last year Claude Code’s consecutive autonomous actions doubled from 9.8 to 21.2, while human turns per transcript fell from 6.2 to 4.1.
The work that remains human is increasingly supervisory, architectural, and judgment-heavy.
And now there’s evidence that the pipeline isn’t just failing to build judgment—it’s failing to hire the people who would have built it. At the start of this month, Anthropic published its own labour market analysis: “Labor market impacts of AI: A new measure and early evidence. Computer programmers are the most exposed occupation at 74.5%—meaning three-quarters of a programmer’s tasks are now seeing significant automated usage in real-world professional settings. At the other end, 30% of workers have zero coverage—cooks, mechanics, lifeguards, bartenders. The physical world remains untouched. For now, at least.”
The paper introduces a measure called “observed exposure” that combines theoretical LLM capability with actual Claude usage data, weighting automated and work-related uses more heavily.
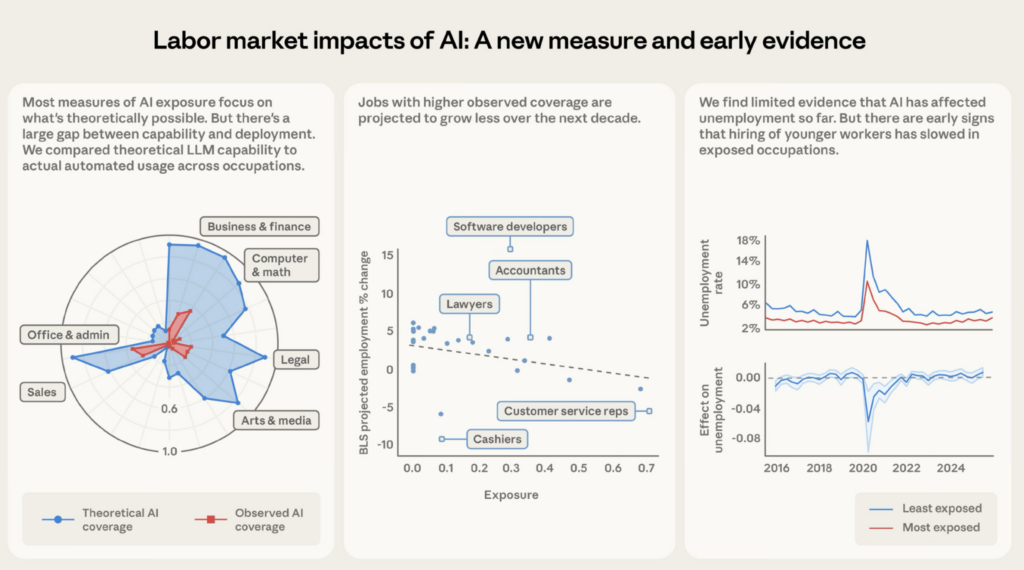
Computer programmers are the most exposed occupation at 74.5%—meaning three-quarters of a programmer’s tasks are now seeing significant automated usage in real-world professional settings. At the other end, 30% of workers have zero coverage: cooks, mechanics, lifeguards, bartenders.
| Occupation | Observed Exposure | Leading Automated Task |
|---|---|---|
| Computer programmers | 74.5% | Write, update, and maintain software programs |
| Customer service representatives | 70.1% | Confer with customers to provide info, take orders, handle complaints |
| Data entry keyers | 67.1% | Read source documents and enter data into systems |
| Medical record specialists | 66.7% | Compile, abstract, and code patient data |
| Market research analysts and marketing specialists | 64.8% | Prepare reports of findings, illustrating data graphically and translating complex findings into written text |
| Sales representatives, wholesale and manufacturing, except technical and scientific products | 62.8% | Contact customers to demonstrate products and solicit orders |
| Financial and investment analysts | 57.2% | Inform investment decisions by analysing financial information to forecast business, industry, or economic conditions |
| Software quality assurance analysts and testers | 51.9% | Modify software to correct errors or improve performance |
| Information security analysts | 48.6% | Perform risk assessments and test data processing security |
| Computer user support specialists | 46.8% | Answer user inquiries regarding computer software or hardware operation to resolve problems |
The physical world remains untouched. For now, at least.
Although I’m not sure given the opportunity to comment back in 90’s in the heat of the first Dotcom boom, before the bust, I would have predicted Uber and the effect the Internet (and the iPhone, which really did change everything) would have on taxi drivers.
AI is far from reaching its theoretical capability. The gap between what LLMs could theoretically do and what they’re actually being used for remains large. Computer and math occupations have 94% theoretical exposure, but only 33% observed coverage. The actual usage is much smaller than theoretical capability across every occupational category.
This is the Amodei gap from the start of the talk, measured precisely.
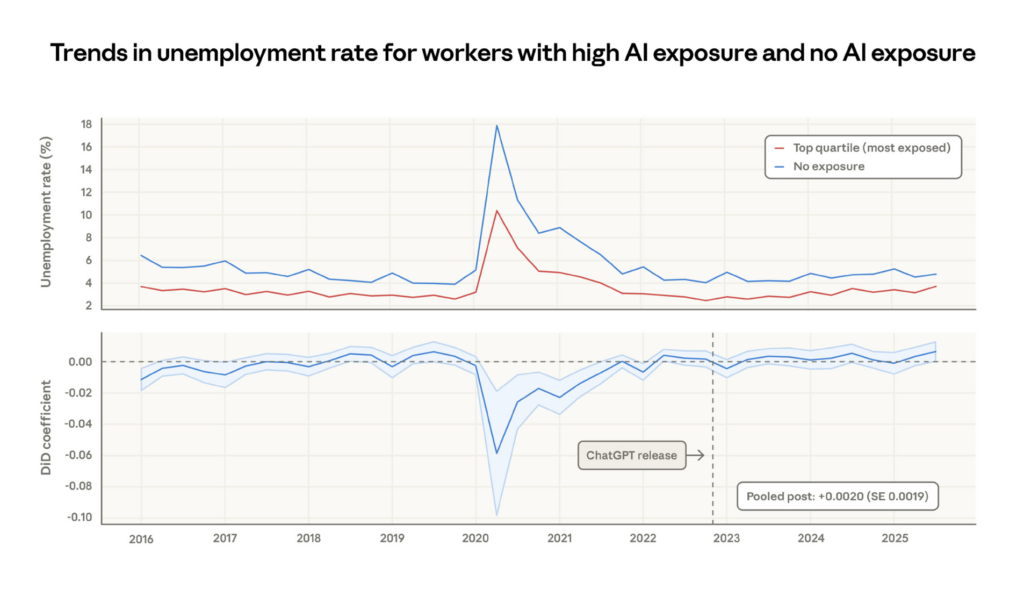
Occupations with higher observed exposure are projected by the Bureau of Labor Statistics to grow less through 2034. For every 10 percentage point increase in AI task coverage, the US government’s growth projection drops by 0.6 percentage points. The labour market analysts are already pricing in the displacement. No systematic increase in unemployment for highly exposed workers, yet.
The unemployment rate for the most AI-exposed occupations hasn’t diverged from the baseline since ChatGPT’s release. This is important: the sky hasn’t fallen. The doom predictions are wrong so far.
But hiring of young workers has slowed in exposed occupations.
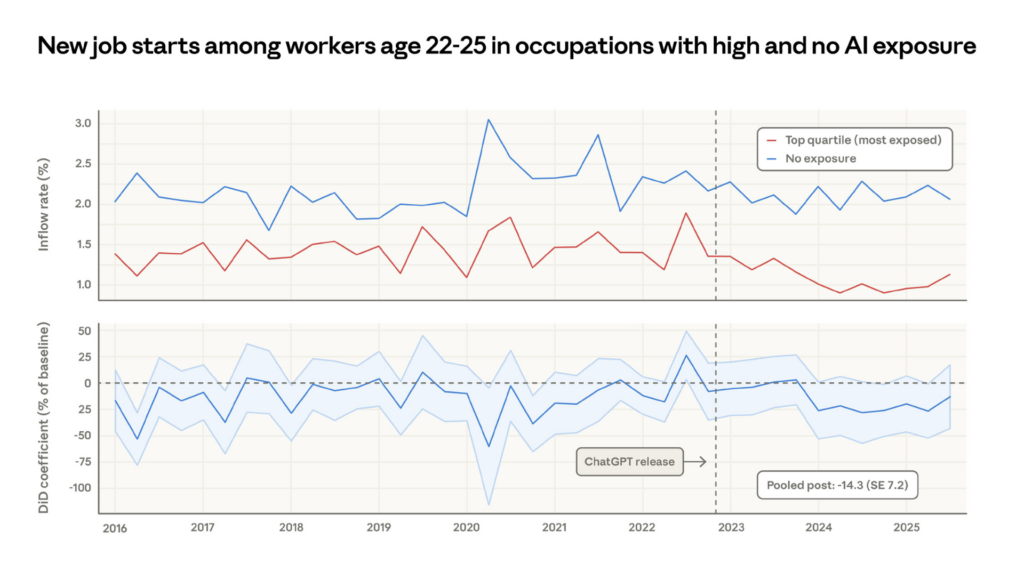
New job starts for 22–25 year olds in AI-exposed occupations visibly diverge downward from unexposed occupations starting in 2024. The averaged estimate is a 14% drop in the job finding rate in exposed occupations compared to pre-ChatGPT levels. There is no such decrease for workers over 25. The paper is honest about caveats—the young workers not being hired may be staying in existing jobs, taking different roles, or returning to education. The result is “just barely statistically significant.” But it echoes independent findings using ADP payroll data. That survey found a 6–16% fall in employment in exposed occupations among workers aged 22 to 25, driven primarily by slowed hiring rather than increased separations.
This is the missing-rungs thesis measured in the labour market. The rungs aren’t just losing their educational function; the jobs themselves are contracting. Companies aren’t firing experienced workers; they’re not hiring the next generation. The pipeline is being cut off at the intake, not the output.
Once again, this is Anthropic publishing these results. The company that builds Claude is documenting the evidence that Claude’s adoption correlates with reduced hiring of young workers into the most exposed professions. Three studies from the same company: AI stunts skill formation, AI transforms work into supervision, and now AI slows hiring at the entry level.
Whatever you think of their motives, the intellectual honesty is remarkable.
Every source, including Anthropic’s own internal research, agrees on this: the organisations racing to adopt AI coding tools are simultaneously degrading the pipeline that produces people capable of supervising those tools. The people who can build good context for AI are the people who built that context in their heads through years of craft. The pipeline that produced those people is breaking. And unlike the story of the home computer disappearing, we don’t yet have the equivalent intervention to Raspberry Pi.
If you came here hoping to hear one, I’m really sorry to disappoint you. But there are no easy answers. Because right now I don’t have a Raspberry Pi shaped piece to fit into an AI shaped hole.
But there are some things we can do now, before we have the full answer.
Structured learning paths. Deliberate rotation through “fundamentals” work, even if AI could do it faster. Like medical residencies, you do the scut work because it teaches you, not because it’s efficient. Require understanding before letting the AI help. It’s expensive. Most companies won’t do it. But the ones who do will have the only senior developers left in ten years’ time. There’s a reason why medical doctors are trained how they’re trained. Still. The robots could do this faster, but that’s not the point.
Measure understanding, not velocity. Can you explain what this code does? Can you debug without AI assistance? What happens if this fails? Pair programming as evaluation: watch how they think, not what they produce.
Treat context as infrastructure. The teams that get AI right are treating their codified context, CLAUDE.md files, memory hierarchies, architectural decision records, as teaching documents, not config files. The best ones read like onboarding docs for a senior engineer who already knows how to code but doesn’t know the codebase. The 26,000-line context architecture isn’t overhead; it’s the institutional knowledge that used to live in people’s heads.
We have entered an era of documentation-first programming. Something I find somewhat ironic, given that the part of the job that most developers hate has now become the whole job.
But most of all we must set honest expectations. We have to tell the juniors that the AI is a tool, not a teacher. Using it to skip understanding is borrowing against your future. The people who’ll be valuable in ten years are the ones who understand the systems, not just the ones who can prompt.
Going back to that original METR study and making a wild arm-waving extrapolation. At the current doubling rate, AI agents will handle tasks equivalent to a full work day by 2027, a full work week by 2028, and a full work month by 2029.
Take that with more than a pinch of salt. I personally don’t believe we’ll get there. Even Moore’s Law broke eventually. But at that point the middle rungs aren’t just missing, the ladder is being rebuilt on a different wall.
If you have ten bakers producing a thousand loaves a month and new ovens let five of them do the same job, you either cut staff or bake more bread. But the city only needs so much bread: and your competitors just bought the same ovens.
However, Anthropic’s data offers one possible escape: 27% of Claude-assisted work consists of tasks that wouldn’t have been done at all without AI: new experiments, nice-to-have tooling, exploratory work.
Not just baking faster, but baking things that weren’t previously worth baking. But that only works if the people supervising the AI baking have themselves learned to bake.
Writing code was a huge bottleneck. Software started out custom-developed within companies for their own use. It only became a mass-produced commodity when demand grew past available supply. The entire SaaS market sits on the shoulders of shortage. A shortage of developers, a shortage of time to build a perfect custom solution for every problem. Instead we are stuck with spreadsheets and web applications designed for most cases.
I’ll give you a personal example. Over the last few months I’ve been building a programming language called Vera, designed specifically for AI-generated code. A language designed for machines to write, not humans.
It’s exactly the kind of project that wouldn’t have been worth even attempting without AI tools. A single person building a compiler, a type system, a test suite, a conformance framework, that used to take a village. AI made it possible for a single person to build something like that. Or at least, a single person with enough experience to know when something smells wrong, to question the architecture, to catch the subtle bugs. To wrangle the AI.
Historically, new technology means more productivity, not fewer jobs. But right now the labour market data says the city is choosing fewer bakers.
Amazon laid off 14,000 corporate workers in October, and then 16,000 more in January.
Anthropic’s own observed-exposure data shows the BLS projecting weaker growth for the most AI-exposed occupations. And the 14% drop in young-worker hiring into exposed jobs suggests the intake to the pipeline is already narrowing, not because the jobs disappeared overnight, but because companies are quietly not replacing the juniors who would have filled them.
The question isn’t whether to adopt AI. That’s a closed question. We’re going to adopt AI, and if you think you won’t, you or your company won’t have a job or a company a year from now.
Instead it’s how to build engineers, ones who can supervise what they never learned to do in the first place. If we don’t solve that problem, nobody will have a company in 10 years time.
Because the ladder isn’t just missing rungs. It’s missing the mechanism that created the people who built the ladder in the first place.