



A model just wrote perfect code in a programming language it has never seen. Moonshot’s Kimi K2.5 scored 100% on a benchmark of 50 coding problems written in Vera, a language with zero examples in any training data. The same model scored just 86% on those problems writing in Python, and 91% writing in TypeScript, two of the most heavily represented languages in every model’s training data.
When I wrote about Vera back in February I was honest about the biggest open question. The compiler worked, although to be fair it works a lot better now. Even then, the language had mandatory contracts, typed slot references, explicit effects, and all the structural guardrails I believed would help models write more correct code. But beliefs aren’t evidence, and the question that actually mattered hadn’t been answered.
I wrote at the time: “Nobody has yet run the experiment at scale to measure whether models actually produce more reliable code in Vera than in existing languages. The thesis is plausible. The tooling exists to test it. The data doesn’t exist yet, and that matters.” Well, the data now exists.
The benchmark
I built VeraBench, a HumanEval-style benchmark suite, specifically to answer this question. It consists of 50 problems spread across five difficulty tiers, from basic arithmetic through to problems involving recursion, string manipulation, and higher-order functions. For each problem, a model is asked to write code in three languages: Vera, Python, and TypeScript. The primary metric is run_correct, which is the simplest measure there is. Does the generated code produce the correct output?
The benchmark asks models to write Vera in two different ways. In full-spec mode, the model receives the complete Vera type signature and contracts, the requires, ensures, and effects declarations, and only needs to write the function body. In spec-from-NL mode, the model receives a natural language description and must infer the contracts itself before writing the code. The second mode is a harder test. It measures not just whether the model can write Vera, but whether it understands the type system well enough to author correct specifications from scratch.
The context, and the thing that makes these results interesting, is that no model has ever been trained on Vera. There are no Vera examples on GitHub. There are no Stack Overflow answers, no tutorials, no blog posts with Vera code in them. Every token of Vera code in these benchmarks was generated by a model that learned the entire language from a single specification document, about 18,000 tokens in total, provided in the prompt at evaluation time.
Python and TypeScript have billions of lines of training data. Vera has none.
The results
VeraBench v0.0.7 tested six models from three providers: Claude Opus 4 and Claude Sonnet 4 from Anthropic, GPT-4.1 and GPT-4o from OpenAI, and Kimi K2.5 and Kimi K2 Turbo from Moonshot.
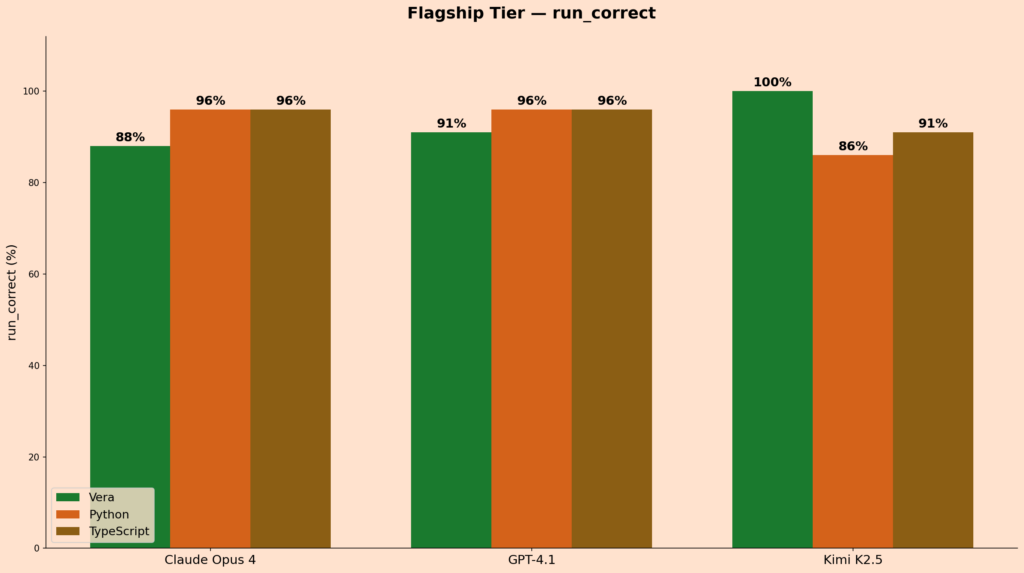
In the flagship tier, Kimi K2.5 is the standout. 100% run_correct on Vera, in both full-spec and spec-from-NL modes, against 86% on Python and 91% on TypeScript. GPT-4.1 scored 91% on Vera, 96% on Python, 96% on TypeScript. Claude Opus 4 scored 88% on Vera, 96% on both Python and TypeScript.
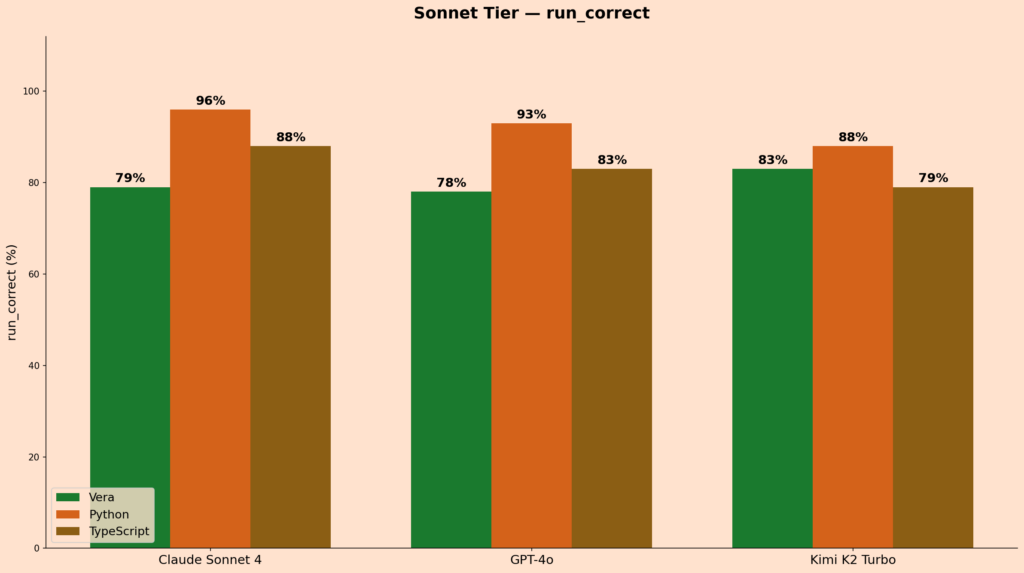
In the Sonnet tier, Kimi K2 Turbo scored 83% on Vera, 83% on Python, and 79% on TypeScript, making it the second model where Vera beats TypeScript outright. Claude Sonnet 4 scored 79% on Vera, 96% on Python, and 88% on TypeScript. GPT-4o scored 78% on Vera, 93% on Python, and 83% on TypeScript. The smaller models struggle more with Vera, which makes sense. Learning a new language entirely from in-context instruction is a harder cognitive task, and the less-capable models have less headroom for it.
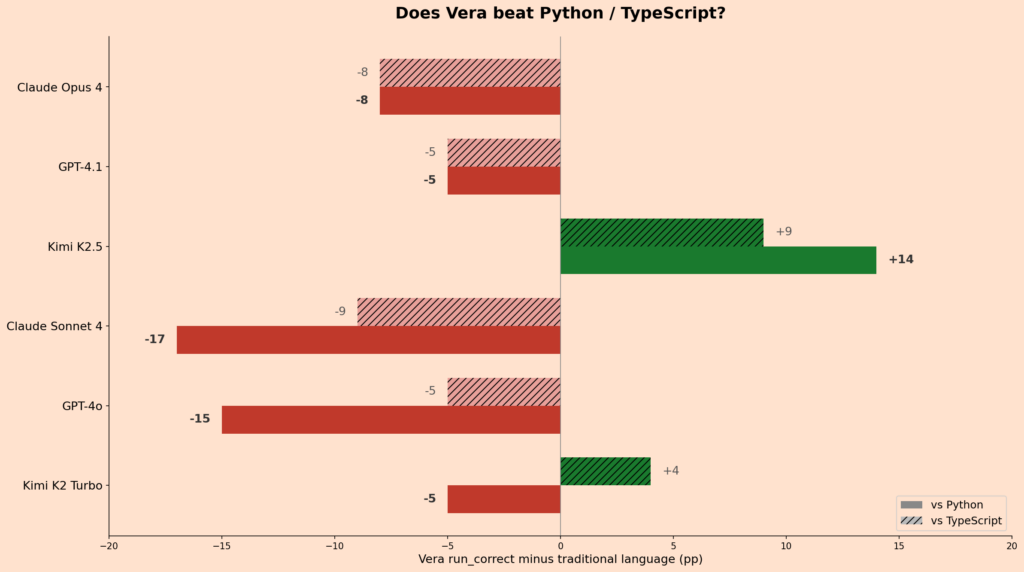
So the number I keep coming back to is the flagship tier average. Across three models from three different providers, Vera averages 93% run_correct. Python averages 93%. That is parity, at least on average, with zero training data.
What this means
There are two ways to read these results.
The conservative reading is that Python still wins for most models, and yes, that’s true. Four out of six models score higher on Python than on Vera. Python’s flexibility means the model doesn’t have to fight a type system. It just has to get the logic right. And for most models, that turns out to be easier.
But the more interesting reading is the one that takes the training data asymmetry seriously. Python is one of the most represented languages in every model’s training corpus. Models have seen billions of lines of Python. They’ve seen every common pattern, every idiom, every way of solving FizzBuzz. They have seen zero lines of Vera. The entire language specification fits in a single prompt. And despite that asymmetry, a language designed around contracts and typed effects is competitive with, and in Kimi’s case better than, the languages models have spent their entire training lives on.
That suggests language design is a meaningful variable in LLM code-generation quality.
It is not the only variable, and perhaps not the most important one for every model. But it’s a variable which, as far as I can tell, almost nobody in the code generation space is paying attention to. Everyone is focused on making models better. Almost nobody is asking whether the languages themselves could be better suited to the models writing them.
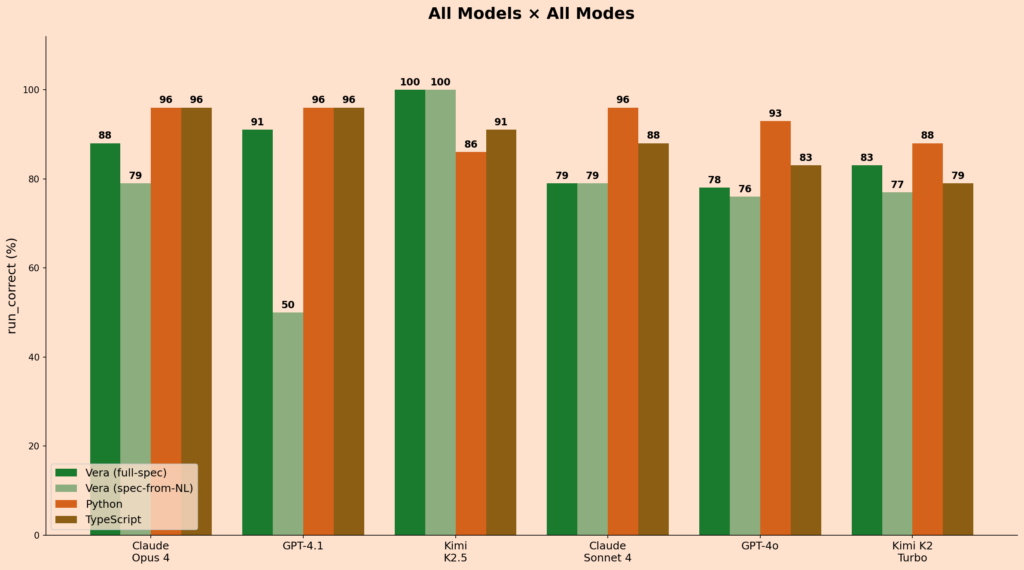
If we look at the all-modes breakdown it tells a more nuanced story. GPT-4.1’s Vera score drops from 91% in full-spec mode to 50% in spec-from-NL mode, which means GPT-4.1 can write correct Vera when given the contracts but struggles to infer them from natural language. While Kimi K2.5 holds at 100% across both modes. That gap, between models that can follow a specification and models that can generate one, is probably the most interesting axis in the data.
What this doesn’t mean
There is a caveat. These are single-run results.
One pass per model, just fifty problems, and models are non-deterministic. Kimi K2.5’s 100% is striking, but it may not reproduce on every run. In the earlier v0.0.4 benchmark, where I only tested Claude Sonnet 4, Vera beat TypeScript 83% to 79%. In the v0.0.7 re-run with the same model, that gap flipped. That kind of variance is inherent to single-pass evaluation and is exactly why these numbers should be treated as directional, not definitive.
Pass@k evaluation, running each problem multiple times per model and measuring how often at least one attempt succeeds, is the next step. It will give a much more stable picture. The benchmark is also small. Fifty problems is enough to see a signal, but not enough to make strong claims about difficulty scaling or failure modes.
I also want to be really clear that the thesis here is not “Vera is better than Python.” I’m not claiming that. Python is a mature language with an enormous ecosystem, and for most practical purposes today it is the better choice for getting things done. The thesis is narrower but (at least I think) somewhat more interesting than that.
I’m proposing that the design of the target language is a variable that affects code generation quality, and that a language designed specifically for models can close a gap that training data alone cannot.
What happens next
Both the language and the benchmark suite are open source. I would welcome people running it against other models, particularly open-weight models that I haven’t yet tested.
The next steps are pass@k evaluation for stable rates, expanding the problem set to stress the contract system harder, and testing against more models as they release. In the longer term I want longitudinal tracking, the ability to re-run the benchmark as both models and the language evolve, and to see whether the trends hold.
But the question I posed in February, whether models write better code in a language designed for them, now has a provisional answer. For at least one model, Kimi-2.5, the answer is an unambiguous “yes”. For the flagship tier as a whole, the answer seems to be “at least as well”. For the broader population of models, the answer is still “it depends, but closer than you’d expect”.
Language design is doing a lot of heavy lifting. So the next question has to be, how much further can it go?